DBCC CHECKDB Last Run Query for Availability Group CHECKDB Monitoring
Running DBCC CHECKDB on every production database is a best practice, some would call it imperative for preventive maintenance. Exceptions exist for identical database copies across servers, but only if you're certain the secondary is disposable and never used for production. Unless that's the case, run CHECKDB everywhere to catch corruption early.
SQL Server 2016 SP2 added LastGoodCheckDbTime to DATABASEPROPERTYEX, tracking the last successful DBCC CHECKDB run (completes without errors). Updates when: Full DBCC CHECKDB succeeds; DBCC CHECKFILEGROUP on all filegroups; even PHYSICAL_ONLY mode. Doesn't update when: DBCC CHECKTABLE (table-level only); ESTIMATEONLY; or CHECKDB finds/skips corruption.
Plainly speaking, this article is about searching for a specific value inside all tables and their columns of a SQL database and return list of tables and columns that contains that value.
That being said, third-party search tools have been around for a long time, as well as custom SQL scripts that you can find online for free, for the purpose of searching for specific values within a database. And even if they don’t meet all your requirements, they at least offer a starting point. However, I realized these solutions weren't sufficient for my specific needs, and I found it easier and quicker to write my own script.
This script uses the dynamic SQL queries to search across all user tables and columns. It does allow you to specify filter criteria to search within a particular schema, table, or column or columns of specific data type groups, for example search inside numeric data only. It also includes commands for exporting table data using PowerShell and BCP utilities, which was one of my requirements.
/* -- CREATE A TEST TABLE FOR DEMO IF OBJECT_ID('my_data_search_table', 'U') IS NOT NULL DROP TABLE my_data_search_table;CREATE TABLE my_data_search_table ( id INT, name VARCHAR(100));INSERT INTO my_data_search_table (id, name)VALUES (1996, 'dummy');*/SET NOCOUNT ON;
USE <Your DB Name Here>;
GO-- Drop temp tables if exists
IF OBJECT_ID('tempdb..#t_table_columns') ISNOTNULLDROPTABLE #t_table_columns;
IF OBJECT_ID('tempdb..#results') ISNOTNULLDROPTABLE #results;
GO-- Search stringDECLARE @search_value NVARCHAR(4000) = N'dummy'; -- Example search value/* Limit what column data types to search into Here, you can specify whether to search within numeric data types, other data types, or both. This helps in narrowing down the search to relevant fields, potentially speeding up the search process and reducing the load on the database.*/
-- valid values are numeric, other or both
DECLARE @search_datatype VARCHAR(10)
-- SET @search_datatype = 'numeric'-- Search modeDECLARE @exact_match BIT = 1;
-- EXECUTION OPTIONSDECLARE @execute BIT = 1; -- 1 to execute the search queriesDECLARE @debug BIT = 0; -- 1 to print onlyDECLARE @show_progress BIT = 1; -- 1 to print progress messagesDECLARE @progress_interval INT = 100;
-- Schema, Table, and Column Filtering (NULL means no filter)DECLARE @search_column_name NVARCHAR(1000);
DECLARE @search_table_name NVARCHAR(1000);
DECLARE @search_schema_name NVARCHAR(1000);
-- Dynamic SQL queryDECLARE @SQL NVARCHAR(4000);
-- If wild card searfch is requested i.e. @exact_match = 0
IF @exact_match = 0 SET @search_value = N'%' + @search_value + N'%';
-- Temp table to store columns metadataSELECT s.name AS [schema_name],
t.name AS [table_name],
c.name AS [column_name],
TYPE_NAME(c.system_type_id) AS [column_type]
INTO #t_table_columns
FROM sys.tables t
JOIN sys.schemas s ON t.schema_id = s.schema_id
JOIN sys.columns cON t.object_id = c.object_id
WHERE t.is_ms_shipped = 0
AND TYPE_NAME(c.system_type_id) NOTIN ('image', 'varbinary');
-- Store list of numeric data types into a table variableDECLARE @numeric_types TABLE (name VARCHAR(100));
INSERTINTO @numeric_types (name)
VALUES
('bigint'),
('bit'),
('decimal'),
('int'),
('money'),
('numeric'),
('smallint'),
('smallmoney'),
('tinyint'),
('float'),
('real');
IF (@search_datatype = 'numeric'AND ISNUMERIC(@search_value) = 0)
BEGIN
RAISERROR('Error: Search value (%s) invalid for numeric search.', 16, 1, @search_value)
GOTO QUIT
END-- Apply filters
IF @search_schema_name ISNOTNULLAND @search_schema_name <> ''DELETEFROM #t_table_columns WHERE [schema_name] <> @search_schema_name;
IF @search_table_name ISNOTNULLAND @search_table_name <> ''DELETEFROM #t_table_columns WHERE [table_name] <> @search_table_name;
IF @search_column_name ISNOTNULLAND @search_column_name <> ''DELETEFROM #t_table_columns WHERE [column_name] <> @search_column_name;
IF @search_datatype ISNOTNULLAND @search_datatype <> ''BEGIN
IF @search_datatype NOTIN ('numeric', 'other', 'both')
BEGIN
RAISERROR('Error: Invalid value %s for @search_datatype.', 16, 1, @search_datatype) WITH NOWAIT
RAISERROR('Valid values are 1) numeric 2) other 3) both.', 16, 1) WITH NOWAIT
GOTO QUIT
ENDELSE IF @search_datatype = 'numeric'DELETE #t_table_columns FROM #t_table_columns t
WHERENOTEXISTS (SELECT * FROM @numeric_types v WHERE v.name = t.[column_type])
ELSE IF @search_datatype = 'other'DELETE #t_table_columns FROM #t_table_columns t
INNERJOIN @numeric_types v ON v.name = t.[column_type]
END-- Placeholder for resultsSELECT TOP 0 * INTO #results FROM #t_table_columns;
-- Progress trackingDECLARE @total_columns INT;
DECLARE @counter INT = 0;
-- Variables for cursorDECLARE @schema_name SYSNAME,
@table_name SYSNAME,
@column_name SYSNAME,
@column_type NVARCHAR(500);
-- Declare cursorDECLARE c1 CURSORSTATICFORSELECT * FROM #t_table_columns
ORDERBY [schema_name], [table_name], [column_name];
OPEN c1;
SELECT @total_columns = @@CURSOR_ROWS;
FETCHNEXTFROM c1 INTO
@schema_name, @table_name, @column_name, @column_type;
WHILE @@FETCH_STATUS = 0
BEGINSET @counter = @counter + 1;
-- Progress message
IF @counter % @progress_interval = 0 AND @show_progress = 1
RAISERROR('%i columns of %i processed', 10, 1, @counter, @total_columns) WITH NOWAIT;
-- Build and execute the search querySET @SQL = N'SELECT TOP 1 ''' + @schema_name + N''' AS [schema_name], '''
+ @table_name + N''' AS [table_name], ''' + @column_name
+ N''' AS [column_name], ''' + @column_type
+ N''' AS [column_type] FROM ' + QUOTENAME(@schema_name)
+ N'.' + QUOTENAME(@table_name) + N' WHERE TRY_CAST('
+ QUOTENAME(@column_name) + N' AS VARCHAR(8000)) LIKE '''
+ @search_value + N''';';
IF @debug = 1 PRINT @SQL;
-- Insert into results if match is found
IF @execute = 1 BEGININSERTINTO #results EXEC (@SQL);
IF @@ROWCOUNT > 0 BEGIN
PRINT '';
RAISERROR('*** match found ***', 10, 1) WITH NOWAIT;
PRINT @SQL;
PRINT '';
ENDENDFETCHNEXTFROM c1 INTO
@schema_name, @table_name, @column_name, @column_type;
END-- CleanupCLOSE c1;
DEALLOCATE c1;
-- Display results with export commandsSELECT *,
'SELECT COUNT(*) [' + [schema_name] + '.' + [table_name]
+ '] FROM ' + QUOTENAME([schema_name]) + '.'
+ QUOTENAME([table_name]) + ' WHERE TRY_CAST('
+ QUOTENAME([column_name]) + ' AS VARCHAR(8000)) LIKE '''
+ @search_value + N''';'AS [SQL],
'Send-SQLDataToExcel -Connection "Server=' + @@SERVERNAME
+ ';Trusted_Connection=True;" -MsSQLserver -DataBase "'
+ DB_NAME() + '" -SQL "select * from '
+ QUOTENAME([schema_name]) + '.' + QUOTENAME([table_name])
+ '" -Path "$env:USERPROFILE\Documents\' + DB_NAME() + '.'
+ [schema_name] + '.' + [table_name] + '.xlsx"'AS [PS Export],
'BCP ' + QUOTENAME(DB_NAME()) + '.' + QUOTENAME([schema_name])
+ '.' + QUOTENAME([table_name]) + ' out %USERPROFILE%\Documents\'
+ DB_NAME() + '_' + [schema_name] + '_' + [table_name]
+ '.txt -c -t, -T -S' + @@SERVERNAME AS [BCP Export]
FROM #results
ORDERBY [schema_name], [table_name], [column_name];
QUIT:
Gotchas and work arounds:
The script does not search within columns of certain data types, notably 'IMAGE' and 'VARBINARY'. These data types often store binary data (e.g., files, images, binary large objects (BLOBs)) that require different methods to search and interpret. Searching within such data types would necessitate additional logic for conversion or binary pattern matching, which is not covered by this script. This is by design.
And for columns with data type VARCHAR(MAX) and NVARCHAR(MAX) that store large amounts of text, the script's default method of casting the column to `VARCHAR(8000)` may truncate data in those columns, possibly missing matches in the truncated portion. You can however modify it to VARCHAR(MAX).
There are also couple performance considerations to keep in mind. The script uses a cursor to iterate over potentially thousands of columns across many tables and executes a dynamic SQL query for each column. This can be resource-intensive and slow, especially in large databases with many tables or columns. As a mitigating action, you can set some filters (e.g., specific schemas or tables, numeric data only etc.).
Similarly, for very huge tables (e.g. billions of rows), the script understandly performs very poorly, especially if the table has no matching records at all but the script will still have to scan all rows for each and every column in it to find out that it doesn't have any matching records after all. You can however limit the performance hit by applying some filters mentioned above.
And because it uses dynamic SQL, it also poses a risk of SQL injection which is why I do not recommend to build a UI around it where users can supply any input values to it. You can however convert the script into a stored procedure and add code to validate and sanitize any inputs passed to it.
I believe the script is highly customizable and moderately detailed enough method for searching data inside a SQL Server database and, designed to accommodate some of the more typical search scenarios and preferences. Please ensure you modify and adapt it to suit your specific requirements.
Finding the Latest Backup Timestamps for Your Databases
I wanted to find out the most recent date and time each database was last backed up, focusing specifically on full, differential, and transaction log backups, all displayed on a single line for each database for easier viewing and reading. For example:
This provides a high-level overview of when my databases were last backed up, including differential and transaction log backups, if applicable. The query results also show the duration of each backup (not shown in the above screenshot). Here is the query:
USE msdb
GO
;WITH cte_latest_backup AS (
SELECT
sd.Name AS DatabaseName,
bs.typeAS backup_type,
MAX(bs.backup_start_date) AS backup_start_time,
MAX(bs.backup_finish_date) AS backup_finish_time
FROM sys.sysdatabases sd
INNERJOIN msdb.dbo.backupset bs
ON bs.database_name = sd.name
GROUPBY sd.Name, bs.type
),
cte_full_backup AS
(
SELECT*FROM cte_latest_backup
WHERE backup_type ='D'
),
cte_diff_backup AS
(
SELECT*FROM cte_latest_backup
WHERE backup_type ='I'
),
cte_tlog_backup AS
(
SELECT*FROM cte_latest_backup
WHERE backup_type ='L'
)
SELECT
d.name AS [Database],
d.recovery_model_desc,
full_backup.backup_start_time AS full_backup_start,
diff_backup.backup_start_time AS diff_backup_start,
tlog_backup.backup_start_time AS tlog_backup_start,
DATEDIFF(MINUTE, full_backup.backup_start_time,
full_backup.backup_finish_time) AS full_backup_elapsed_min,
DATEDIFF(MINUTE, diff_backup.backup_start_time,
diff_backup.backup_finish_time) AS diff_backup_elapsed_min,
DATEDIFF(SECOND, tlog_backup.backup_start_time,
tlog_backup.backup_finish_time) AS tlog_backup_elapsed_sec
FROM master.sys.databases d
LEFTJOIN cte_full_backup full_backup
ON full_backup.DatabaseName = d.name
LEFTJOIN cte_diff_backup diff_backup
ON diff_backup.DatabaseName = d.name
LEFTJOIN cte_tlog_backup tlog_backup
ON tlog_backup.DatabaseName = d.name
WHERE d.name NOTIN ('tempdb')
ORDERBY [Database]
Gotchas:
The query doesn't capture other available types of backups like file backup, file group backups, partial backups etc. If your backup strategy includes any of those backup types, please consider adapting the query to meet your needs.
The query doesn't also differentiate whether the full backup was done in copy-only mode or not.
In AlwaysOn AG servers, some of your database backups maybe offloaded or distributed across primary and secondary replicas. This query doesn't capture backups performed on other replicas and therefore the most recent backup date/times displayed by the query may not be accurate for databases that are in an Availability Group.
How to Find Where Your Databases Reside In The File System
SQL Script:
/***************************************************************************************** Script: Get SQL Server Database File Folder Locations Purpose: Returns DISTINCT list of all folders containing SQL Server database files (data + log + FILESTREAM) across all databases on the instance. Features: * Works on SQL Server 2000-2025 * Generates TWO create-directory methods: - xp_create_subdir: T-SQL for Windows/SQL Agent jobs (xp_cmdshell required) - mkdir -p: Linux shell commands for backup/migration targets * Falls back to legacy method if VIEW SERVER STATE denied or old version Usage: Run as sysadmin or user with VIEW SERVER STATE permission******************************************************************************************/SETNOCOUNTON;
DECLARE@PRODUCTVERSIONNVARCHAR(132)
DECLARE@PERMISSION_FLAGbit=1-- Set to 0 to force legacy path (testing)-- Get major version number (e.g. '15' for SQL 2019, '16' for 2022)SET@PRODUCTVERSION=CAST(SERVERPROPERTY('ProductVersion')ASNVARCHAR(32))-- Extract major version: everything before first decimal pointDECLARE@MAJOR_VERSIONINT=CAST(SUBSTRING(@PRODUCTVERSION,1,CHARINDEX('.',@PRODUCTVERSION)-1)ASINT);
-- LEGACY PATH: SQL Server 2000-2008R2 OR no VIEW SERVER STATE permissionIF@MAJOR_VERSION<10OR@PERMISSION_FLAG=0BEGINPRINT'Using legacy method (SQL 2000-2008R2 compatibility or VIEW SERVER STATE denied)...';
-- Clean up any existing temp tableIFOBJECT_ID('tempdb..#t1')ISNOTNULLDROPTABLE#t1;
-- Temp table to hold folder paths and filenames from sysfilesCREATETABLE#t1(
fpathVARCHAR(4000),-- Folder path onlyfnameVARCHAR(8000)-- Full filename for reference);
-- sp_MSforeachdb visits every DB on instance (undocumented but reliable)INSERTINTO#t1(fpath,fname)
EXECsp_MSforeachdb' SELECT LEFT(filename, LEN(filename) - CHARINDEX(''\\'', REVERSE(RTRIM(filename)))) AS fpath, filename AS fname FROM [?].dbo.sysfiles ';
SELECTDISTINCTfpathASfolder_path
FROM#t1ORDERBYfpath;
DROPTABLE#t1;
END-- MODERN PATH: SQL Server 2012+ with sys.master_files (recommended)ELSEBEGINPRINT'Using modern sys.master_files method (SQL 2012+)...';
WITHcteAS(
SELECTCASE-- FILESTREAM files (type=2) use full physical_name as "folder"WHENtype=2THENphysical_name-- Regular files: strip filename to get folder pathELSELEFT(physical_name,LEN(physical_name)-CHARINDEX('\',REVERSE(RTRIM(physical_name))))ENDASfolder_path,physical_nameFROMsys.master_files
WHEREtypeIN(0,1,2)-- ROWS, LOG, FILESTREAM only)
SELECTDISTINCTfolder_path,
'EXEC master.dbo.xp_create_subdir N'''+folder_path+''''ASxp_create_subdir,
'mkdir -p "'+folder_path+'"'AScreate_folder
FROMcte
ORDERBYfolder_path;
END
This SQL script is designed to return a list of distinct folder paths where SQL Server database files are stored. It adapts its behavior based on the version of SQL Server it's running against and whether specific permissions are set.
The output of the script includes a column with command to create directories, using SQL command xp_create_subdir (preferred) or using mkdir -p methods, useful in cases where this script is part of a larger process, perhaps in database migrations or backups.
Use Cases:
Finding the folder paths where SQL Server database files are stored can be beneficial for several operational, management, and maintenance tasks related to database administration and infrastructure management. Here are some key use cases:
1. Backup and Restore Operations
- Backup Scripts: Knowing the folder paths helps in scripting backup operations, especially when you want to NOT save the backup files in the same location as the database files or in a related directory structure.
- Restore Operations: When restoring databases, especially to a new server or instance, knowing the original file locations can be crucial for planning the restore process, particularly if you need to maintain a specific directory structure or adhere to storage policies.
2. Disaster Recovery Planning
- Identifying the storage locations of database files is essential for creating effective disaster recovery plans. It allows administrators to ensure that all necessary files are included in backups and can be quickly restored in case of a failure.
3. Capacity Planning and Monitoring
- Storage Management: Monitoring the disk space usage of SQL Server file paths can help in forecasting future storage requirements and preventing disk space shortages that could lead to database downtime.
- Performance Optimization: File placement can significantly impact database performance. Knowing where files are stored enables DBAs to distribute files across different storage subsystems based on performance characteristics.
4. Database Migration
- When migrating databases between servers or instances, it's important to know the current storage paths to replicate the environment accurately on the target server or to plan new storage configurations that improve performance or resource utilization.
5. Auditing and Compliance
- For compliance with internal policies or external regulations, it may be necessary to verify that database files are stored on secure, encrypted, or approved storage devices. Knowing the file paths helps in auditing these practices.
6. Server and Storage Configuration
- High Availability (HA) and Disaster Recovery (DR) Solutions: Configuring solutions like Always On Availability Groups, Database Mirroring, or Log Shipping often requires precise control over file locations.
- Storage Optimization: Identifying file locations helps in moving files to optimize storage across different media (SSDs, HDDs) or to balance I/O load.
7. Troubleshooting and Maintenance
- When dealing with file corruption, access issues, or performance problems, knowing the exact location of database files is the first step in diagnosing and resolving such issues.
8. Automated Scripting and Tooling
- Automating database tasks such as backups, file growth monitoring, or applying storage policies often requires scripts that know where database files are located. Scripts may also need to create or modify directories based on these paths.
Understanding and Using xp_sqlagent_enum_jobs in SQL Server
What is xp_sqlagent_enum_jobs?
xp_sqlagent_enum_jobs is an undocumented, extended stored procedure in Microsoft SQL Server. It is used to provide information about the jobs that are currently managed by the SQL Server Agent. This extended stored procedure is used in some internal procedures (e.g. sp_get_composite_job_info) by SQL Server, but it can also be used in custom scripts or applications to obtain details about SQL Agent jobs, especially in automated scripts or applications that need to track job status or performance. For example:
Often, the main impetus for using xp_sqlagent_enum_jobs is to programmatically check if a SQL Server Agent job is currently running, and then either wait for it to complete or take some other action. While interactive tools are available for monitoring job status, there aren't many reliable and well-documented stored procedures, system tables, or DMVs suitable for use in automated, non-interactive scenarios.
Syntax and Usage:
xp_sqlagent_enum_jobs typically requires that minimum two input parameters are given and, a third optional parameter. However, since this procedure is undocumented, the exact nature and behavior of these parameters might vary slightly based on the version of SQL Server. Here is a general explanation of its parameters:
Visibility Flag / is_sysadmin (Int): This parameter is usually an integer 0 or 1 to indicate if the executing user is a sysadmin (member of sysadmin role) and determines the scope of the job information returned by the procedure. A value of 1 indicates Yes and the procedure can return information for all jobs. A value of 0 means No in which case the procedure will return only those jobs that are owned by the executing user or jobs that the user has been granted permissions to view.
In my experience though, xp_sqlagent_enum_jobs seems to accept not only 0 or 1 but various integer values, both positive and negative.
Job Owner (Sysname): This is a string parameter representing the user in the context of whom the job information is requested. It's often provided in the format of a domain and username (e.g., DOMAIN\Username) or 'sa' if a DBA is running this procedure. This parameter is used along with the the visibility flag to determine which jobs are visible to the specified user based on their permissions.
Again in my experience, xp_sqlagent_enum_jobs seems to accept any value, including invalid or non-existent usernames.
Job ID (UNIQUEIDENTIFIER): Optional parameter to get information for a single job with a specific job ID.
If you are getting Job ID value from the msdb.dbo.sysjobs table, make sure to convert its value to a UNIQUEIDENTIFIER data type.
Basic Examples:
In this example, 1 is the visibility flag, and 'sa' represents the user.
EXEC master.dbo.xp_sqlagent_enum_jobs 1, 'sa'
To get information about a specific job:
DECLARE@job_name NVARCHAR(100) ='DatabaseIntegrityCheck - USER_DATABASES'DECLARE@job_id UNIQUEIDENTIFIER
SELECT@job_id = job_id FROM msdb..sysjobs WHERE NAME =@job_name
EXEC master.dbo.xp_sqlagent_enum_jobs1, 'sa', @job_id
When using xp_sqlagent_enum_jobs, consider the following:
Permissions: The actual jobs returned can depend on the permissions of the user executing the procedure or the user specified in the parameters.
Security Risk: As an undocumented feature, using this procedure can pose a security risk, especially if used improperly or without understanding its impact.
Version Dependence: The behavior and availability of xp_sqlagent_enum_jobs can change without notice in different versions of SQL Server.
Results/Output Columns:
The procedure returns a result set with various columns providing details about each job. These details typically include:
Job ID: A unique identifier for each job.
Last Run Date: The date and time when the job was last executed.
Next Run Date: The date and time when the job is scheduled to run next.
Next Run Schedule ID: The identifier of the schedule according to which the job will run next.
Requested To Run: Indicates whether the job has been requested to run immediately (outside its scheduled times).
Request Source: Indicates the source of the run request.
Request Source ID: The identifier of the request source.
Running: Indicates whether the job is currently running.
Current Step: The current step number the job is on (if it's a multi-step job).
Current Retry Attempt: The number of the current retry attempt (in case the job is configured to retry on failure).
State: The current state of the job.
What does it mean that xp_sqlagent_enum_jobs is undocumented?
xp_sqlagent_enum_jobs is indeed an undocumented extended stored procedure in Microsoft SQL Server. This means that it is not officially documented or supported by Microsoft in their public documentation. In essence, this raises several important considerations:
Lack of Official Documentation: Since there's no official documentation, detailed information about its parameters, behavior, and potential changes in different versions of SQL Server are not publicly available through Microsoft's channels.
Potential for Change: Microsoft may change or remove undocumented features in any new release or update of SQL Server without prior notice. This can lead to compatibility issues or sudden breaks in functionality in systems that rely on these features.
Limited Support: If you encounter issues while using undocumented features, finding solutions can be more challenging as these features are typically not covered by standard support channels.
Use with Caution: It's advisable to use undocumented features with caution, especially in production environments. They might be less stable or tested compared to officially supported features.
Alternative Approaches: For long-term stability and support, it's often better to seek alternative, documented features or methods to achieve the same goals.
Community Knowledge: Sometimes, information about undocumented features can be found through community forums, blogs, or from SQL Server experts who share their findings. However, this information is based on personal experiences and might not be universally applicable.
Usage Scenerios:
Here are a few example scenarios of how xp_sqlagent_enum_jobs might be used:
Basic Usage to List All SQL Agent Jobs
This is the simplest form of using xp_sqlagent_enum_jobs to get a list of all SQL Agent jobs with their details.
Use a Dedicated Account: When specifying the user account (<your_domain\your_login>), it's best to use an account with appropriate permissions.
Temporary Tables: In the examples, I've used temporary tables (#RunningJobs) to store the output of xp_sqlagent_enum_jobs. This is a common practice to make data handling easier.
Cleanup: Always remember to clean up temporary tables to avoid unnecessary consumption of resources.
Testing: Thoroughly test these scripts in a non-production environment first to ensure they work as expected in your specific SQL Server setup.
Monitoring and Logging: When using such procedures in scripts or applications, implement adequate logging and error monitoring.
Seek Alternatives: While I haven't tried or tested the following myself, here is an article discussing one of the possible alternatives:
SQL Server's Buffer Cache: How to Calculate Dirty Page Sizes
"Almost" everything SQL Server does happens through the buffer pool. Here, the buffer "pool" is a combinations of memory regions used by SQL Server. The largest and main region is the "buffer cache," which is why most discussions about SQL Server's inner workings, including performance issues and solutions, involve the buffer cache.
For example, if a query needs to read a page, it will be served from the buffer cache... if the requested page is not in there then it will be fetched from the disk into the buffer cache first, then served to the query. And if a query modifies a page, that too gets modified in the buffer cache first... then some other internal SQL Server processes will copy the modified pages from buffer cache to the disk.
Additionally, the buffer cache also contains data that doesn't yet exist on the disk (in SQL Server data files). This includes new data when it's added. Although SQL Server immediately writes this data to the transaction log file (unless Delayed Durability is enabled), it's not immediately written to the data files. Instead, SQL Server waits until the next CHECKPOINT process, which then writes these "dirty" pages to the data files. The LAZY WRITER process also writes dirty pages to the disk, but it does so continuously in a less aggressive manner.
There are exceptions though where SQL Server may bypass the buffer cache entirely and performs the direct disk I/O, for example for bulk load and bulk inserts.
Primarily, the buffer cache's job is to reduce the amount of time SQL Server spends reading data from the disk. It does this by keeping frequently accessed data in memory, which is much faster to access than disk storage.
Why size of dirty pages matters:
There are few reasons why you may want to track the amount and size of dirty pages in buffer pool, especially if it's too high as it is often an indicator of or contributes to slower performance, potentials of data loss and increased recovery and/or start up times.
Causes:
Some reasons I can think of top of my head are:
A simple and likely reason is that you have relatively high number of writes i.e. high number of INSERTS, UPDATES, and/or DELETES. Or that you have very large, long running transactions in progress, generating significant amount of dirty pages.
There is a memory pressure or more accurately the buffer pool is under pressure and can't write dirty pages to disk fast enough. This could be an indication that not enough memory is allocated to SQL Server or a more likely explanation is that your database needs a tuning.
The disk I/O is slow, i.e., the I/O subsystem is the bottleneck, causing a high count of dirty pages. Bluntly speaking, if you have slower disks, it can cause longer I/O queue length and a backlog of dirty pages waiting to be written to disk. Of course, the impact of slow I/O would be felt and manifested in several ways.
Heavy use of temporary tables can also cause high number of dirty pages
If the interval between checkpoints is too long then dirty pages can build up in the buffer pool.
Calculating size of dirty pages:
To calculate the size of the dirty pages in buffer cache, SQL Server exposes some meta data regarding the pages in buffer cache through sys.dm_os_buffer_descriptors DMV. Though I am not a fan, this still is the primary way to ascertain and monitor the size of dirty pages.
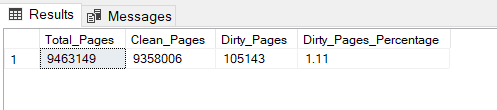
If you have VIEW SERVER STATE permission or, the SYSDBA role membership, you can query sys.dm_os_buffer_descriptors, mostly to get some summary information as it only contains the meta data. The below query is an example of such, which returns the ratio/percentage of dirty pages against the overall/total size of the buffer cache.
A word of caution: if you have a very large buffer cache (like 750GB or even 75GB), querying this DMV can be very very slow. The larger the cache, the more data the DMV has to process. For a 75GB cache, it might need to process about ~10 million rows; for a 750GB cache, that number could jump to ~100 million rows!
Please also note that when using the sys.dm_os_buffer_descriptors tool to view the buffer cache contents, keep in mind that it also includes pages used by SQL Server's internal Resource database. Often, these pages are left out when people are summing up or analyzing the buffer cache data. However, in this particular example, I've chosen to include them in the count and analysis.
Alternative Method:
If you have huge buffer cache like 2TB or more, using sys.dm_os_buffer_descriptors can be impractical. While not as detailed, you can utilize the DBCC MEMORYSTATUS to get the size of dirty pages:
IF OBJECT_ID('tempdb..#MemoryStatus') ISNOTNULLDROPTABLE#MemoryStatus;
CREATETABLE#MemoryStatus (
ID INTIDENTITY(1,1) PRIMARYKEY,
NAME NVARCHAR(100),
VALUE BIGINT
);
INSERTINTO#MemoryStatus (NAME, VALUE)
EXEC ('DBCC MEMORYSTATUS WITH TABLERESULTS');
SELECTCASEWHEN NAME='Database'THEN'Buffer Pages'WHEN NAME='Dirty'THEN'Dirty Pages'ELSE NAME END NAME,
VALUE /128 SIZE_MB
FROM#MemoryStatus
WHERE NAME in ('Database','Dirty');
I would really prefer using windows performance counters for this but alas... there are no windows performance counters currently available that would measure size of the dirty pages. There are some performance counters (e.g. Checkpoint pages/sec) can be used to get some idea about the size of dirty pages, I have though found them to be not adequate or accurate enough.